
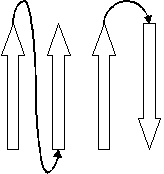
10A should also be red
same as 10B
Just as Dr. Kister said, when black SM has odd number of strandons, there's something wrong.
Now we know, SOMETHING=RED.
Just as Dr. Kister said, when black SM has odd number of strandons, there's something wrong.
Now we know, SOMETHING=RED.
posted by 蘇老師 | 11:09 PM
|
0 comments
![]()
{kind=link}