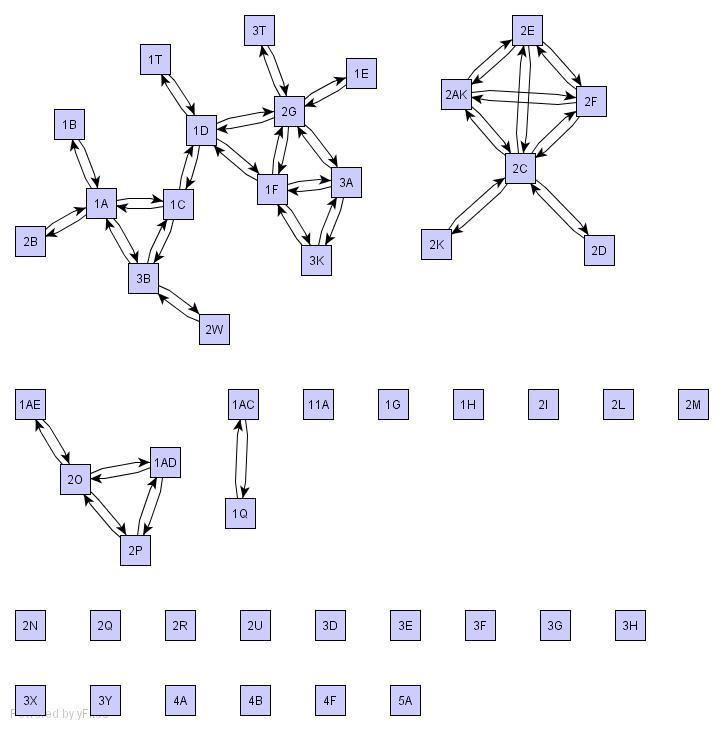
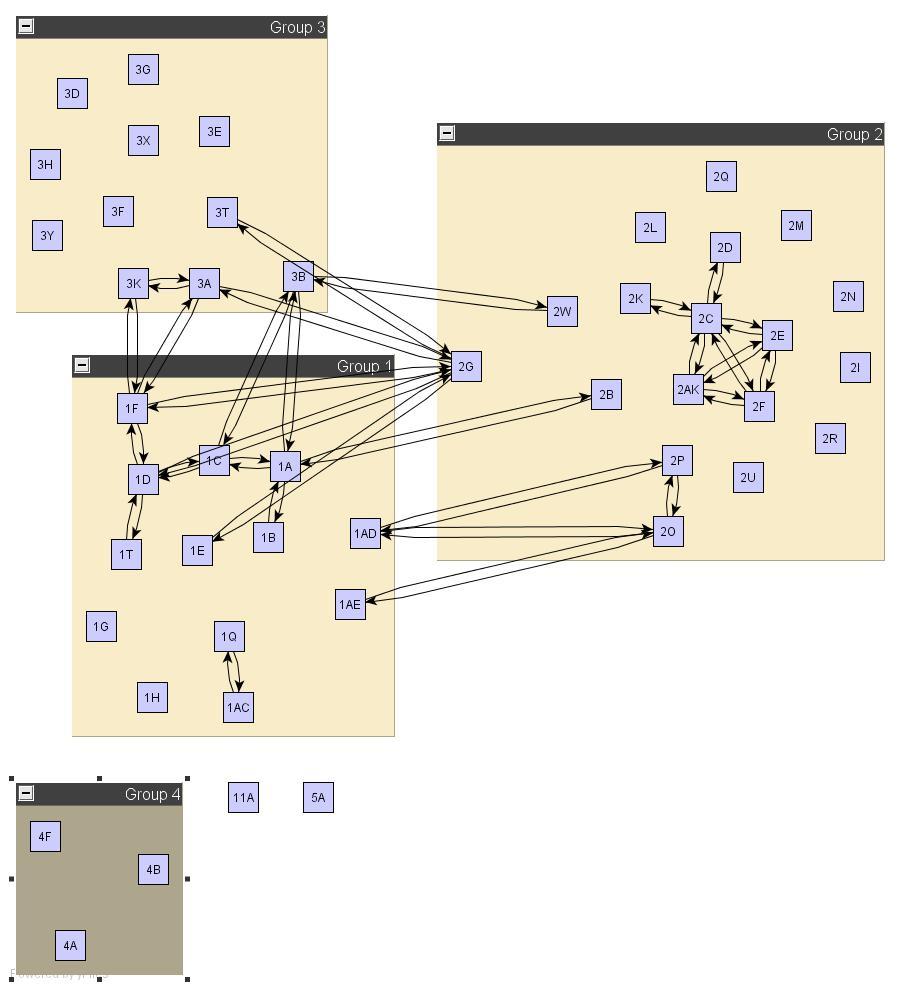
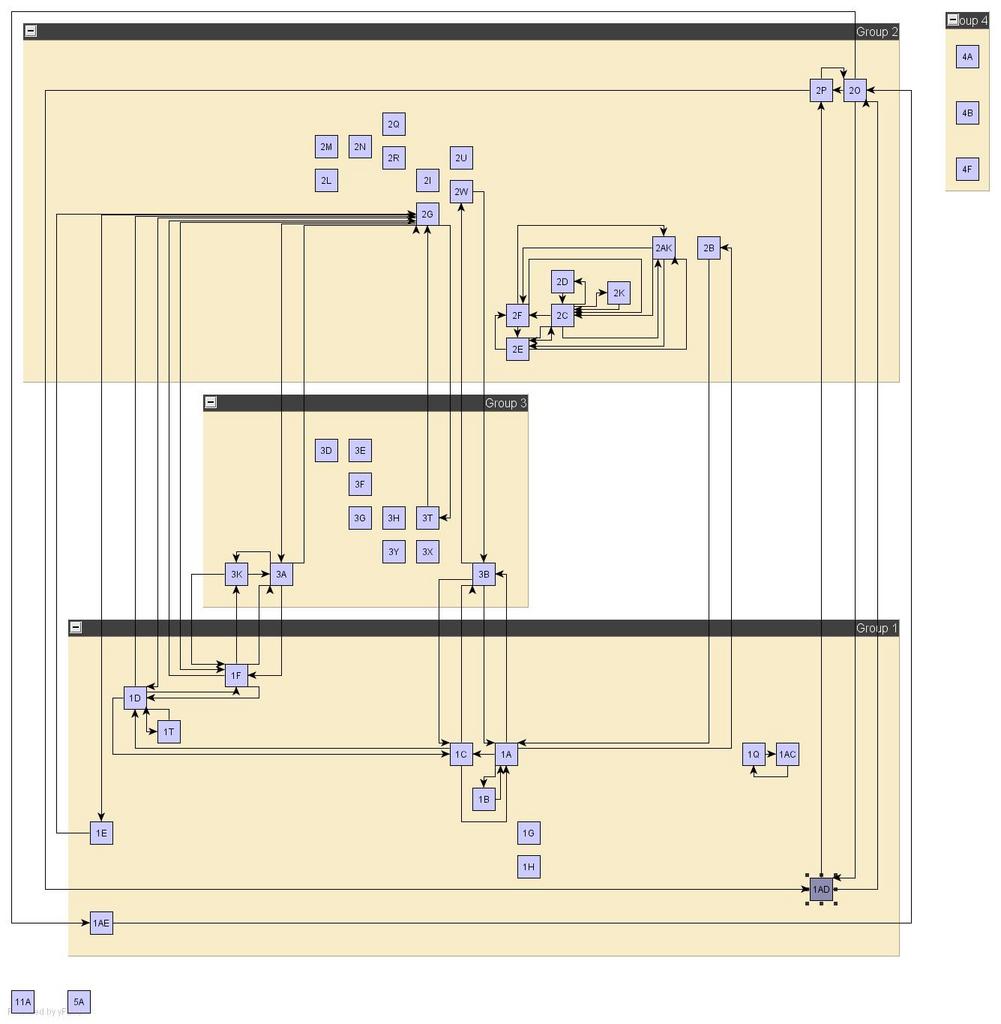
idea
to plot hits on two trees, we can use microarray style graph.
ex: one tree for scop, another tree for motifs.
ex: one tree for scop, another tree for motifs.
posted by 蘇老師 | 5:59 PM
|
0 comments
![]()

posted by 蘇老師 | 5:59 PM
|
0 comments
![]()
posted by 蘇老師 | 12:21 PM
|
0 comments
![]()
posted by 蘇老師 | 12:06 PM
|
0 comments
![]()
posted by 蘇老師 | 5:07 PM
|
0 comments
![]()
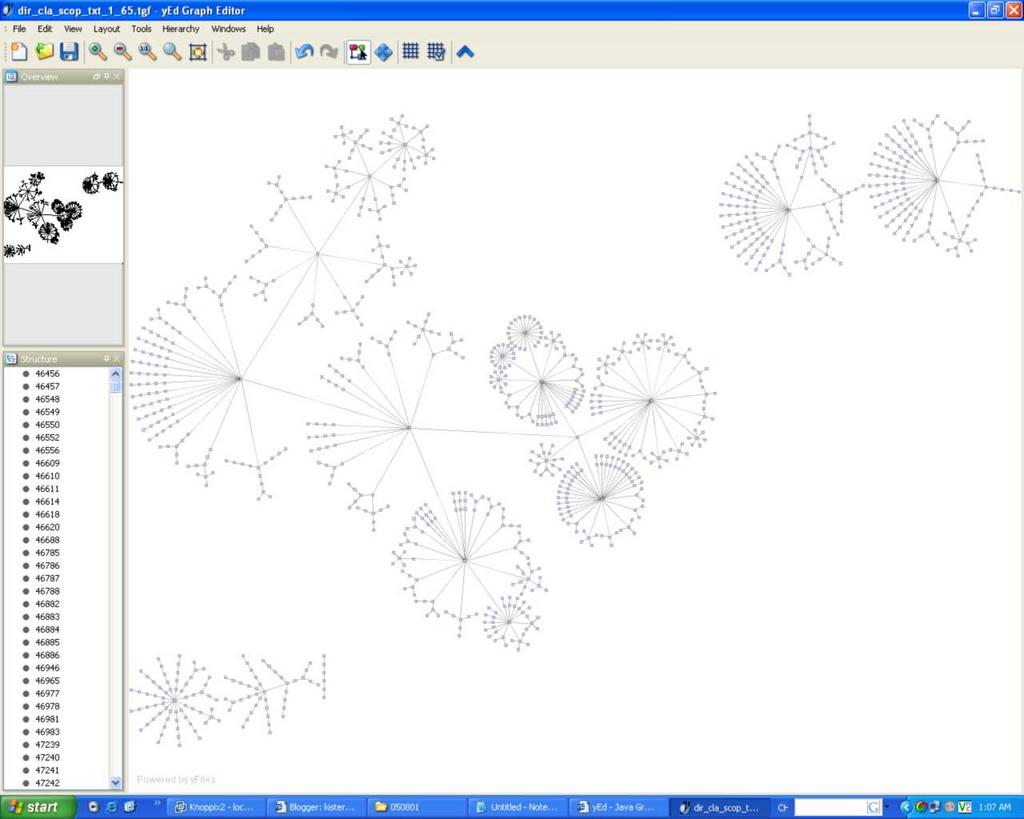
posted by 蘇老師 | 10:11 PM
|
0 comments
![]()
posted by 蘇老師 | 9:57 PM
|
0 comments
![]()
posted by 蘇老師 | 12:24 PM
|
0 comments
![]()
posted by 蘇老師 | 1:07 PM
|
0 comments
![]()
posted by 蘇老師 | 12:52 PM
|
0 comments
![]()
WEATA
[AIV]-[DEKNTVY]-[FL]-[DHLNPST]-[CFIV]
AVSQFNAR
QFNA=[FGILMV]-[EFHKLRTY]-[LW]-[EKLQRY] in 3B
KIYFDV
[AFGLSW]-[DGHPST]-[IL]-[IKNQRTV]-[FILV]-[HKLPSTY]
SPTIVAM
[AEIKNQST]-[ADG]-[EFILST]-[FGY]-[EIKLNQTY]-[CLMV]-[ADEIKMSTV]
posted by 蘇老師 | 10:33 AM
|
0 comments
![]()
i
v-t-l-t-c
compare to 3B:[AIV]-[DEKNTVY]-[FL]-[DHLNPST]-[CFIV]-
i+1
t-v-h-w-v
compare to 3B:[ADSQERV]-[FGILMV]-[EFHKLRTY]-[LW]-[EKLQRY]
k
R-R-L-L-L-R-S-V-Q
compare to 3B:[AFGLSW]-[DGHPST]-[IL]-[IKNQRTV]-[FILV]-[HKLPSTY]-[AHNPQS]-[ALV]-[DKQRST]
k+1
S-G-N-Y-S-C-Y
compare to 3B:[AEIKNQST]-[ADG]-[EFILST]-[FGY]-[EIKLNQTY]-[CLMV]-[ADEIKMSTV]
posted by 蘇老師 | 6:16 PM
|
0 comments
![]()
posted by 蘇老師 | 5:45 PM
|
0 comments
![]()
3A not including 1kv3
i
[VIAL]-[TRLHEV]-[IVLF]-[STPRAMV]-C-[tsiqdkr]-[GAFYV]
i+1
[IHKSYGTQ]-[WL]-[YFCTLIK]-[QYRK]-[QHDAEF]
k
[AVCFSEK]-[STNEVG]-[LVF]-[ATLSIHY]-[IML]-[STKRF]-[GDNK]-[LVA]-[EQKRDST]
k+1
[DE]-[ESAI]-[AG]-[DTRHEL]-[YL]-[YNFWIT]-[FC]-[AQSRILKE]
pattern not in interlock
[GQRTSN]-[TLFIAY]-[KRTSYHWL]-[LVT]-[TNVKH]
posted by 蘇老師 | 2:32 PM
|
0 comments
![]()
posted by 蘇老師 | 1:17 PM
|
0 comments
![]()
posted by 蘇老師 | 2:34 PM
|
0 comments
![]()
posted by 蘇老師 | 8:31 AM
|
0 comments
![]()
posted by 蘇老師 | 7:26 PM
|
0 comments
![]()
posted by 蘇老師 | 3:31 PM
|
0 comments
![]()
posted by 蘇老師 | 9:51 AM
|
0 comments
![]()
posted by 蘇老師 | 9:38 AM
|
0 comments
![]()
P-X-[VLITAM]-X-[ILPTAV]-X(0,16)-[VLI]-X-C-X-[LMIAV]-X-X-[FILY]-X-P-X-X-[IAVL]-X-[VFTLIM]-X-[WLMF]-X(0,25)-[DNGST]-X-X-[YFW]-X(1,5)-[LVAT]-X-[LVFIM]-X(1,25)-[YVFIL]-X-C-X-[VAM]-X-[FH]-X(1,27)-[FLVIWAY]
has to be shorten too.
posted by 蘇老師 | 9:30 AM
|
0 comments
![]()
posted by 蘇老師 | 9:21 AM
|
0 comments
![]()
posted by 蘇老師 | 9:09 AM
|
0 comments
![]()
posted by 蘇老師 | 8:46 AM
|
0 comments
![]()